Publications
A page about publications.
2025
-
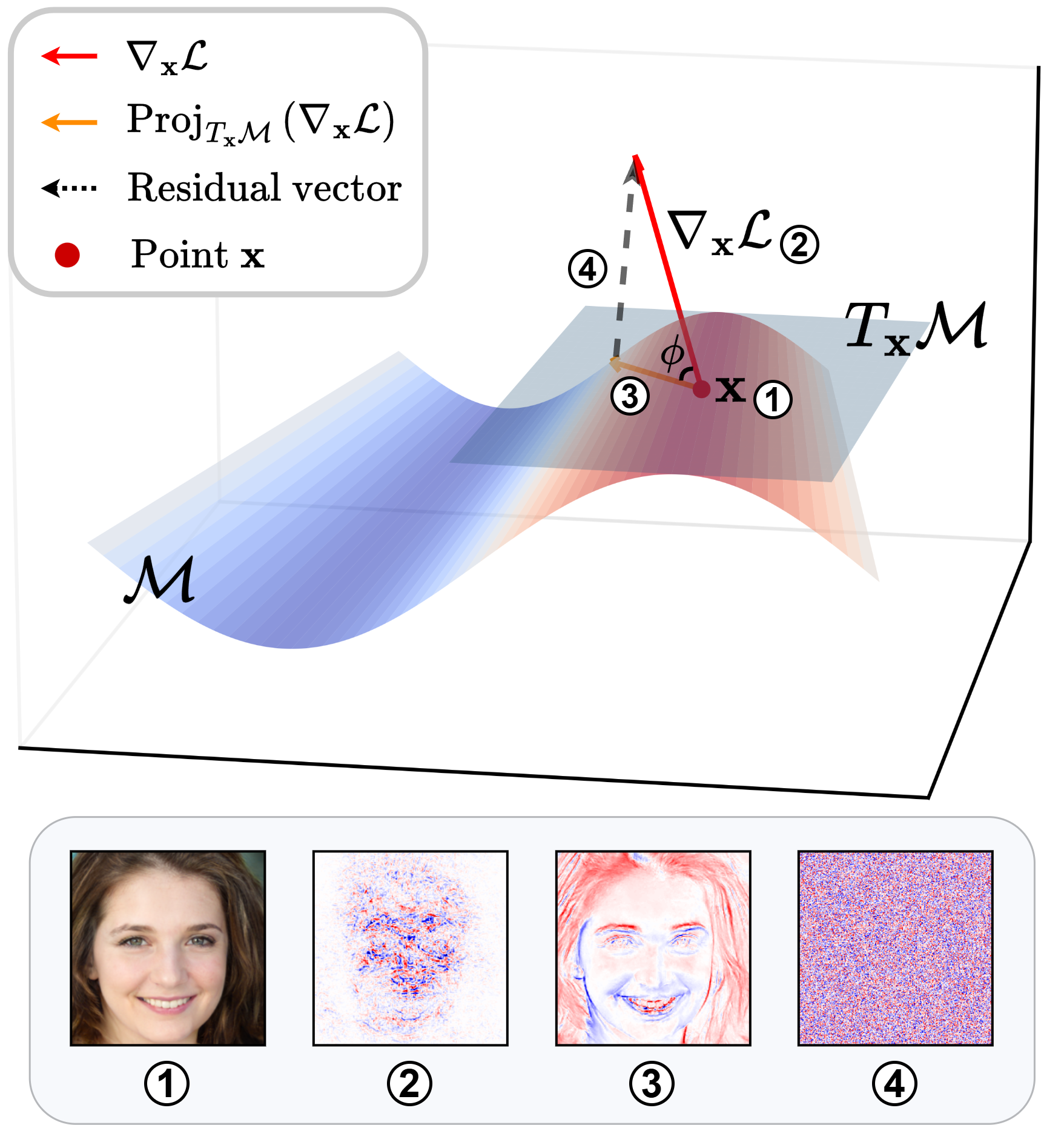 Generative Model Inversion Through the Lens of the Manifold HypothesisXiong Peng, Bo Han, Fengfei Yu, and 3 more authorsAdvances in Neural Information Processing Systems, 2025
Generative Model Inversion Through the Lens of the Manifold HypothesisXiong Peng, Bo Han, Fengfei Yu, and 3 more authorsAdvances in Neural Information Processing Systems, 2025Model inversion attacks (MIAs) aim to reconstruct class-representative samples from trained models. Recent generative MIAs utilize generative adversarial networks to learn image priors that guide the inversion process, yielding reconstructions with high visual quality and strong fidelity to the private training data. To explore the reason behind their effectiveness, we begin by examining the gradients of inversion loss w.r.t. synthetic inputs, and find that these gradients are surprisingly noisy. Further analysis reveals that generative inversion implicitly denoises these gradients by projecting them onto the tangent space of the generator manifold, thereby filtering out off-manifold components while preserving informative directions aligned with the manifold. Our empirical measurements show that, in models trained with standard supervision, loss gradients often exhibit large angular deviations from the generator manifold, indicating poor alignment with class-relevant directions. This observation motivates our central hypothesis: models become more vulnerable to MIAs when their loss gradients align more closely with the generator manifold. We validate this hypothesis by designing a novel training objective that explicitly promotes such alignment. Building on this insight, we further introduce a training-free approach to enhance gradient-manifold alignment during inversion, leading to consistent improvements over state-of-the-art generative MIAs.
@article{peng2025generative, title = {Generative Model Inversion Through the Lens of the Manifold Hypothesis}, author = {Peng, Xiong and Han, Bo and Yu, Fengfei and Liu, Tongliang and Liu, Feng and Zhou, Mingyuan}, journal = {Advances in Neural Information Processing Systems}, year = {2025}, }
2024
-
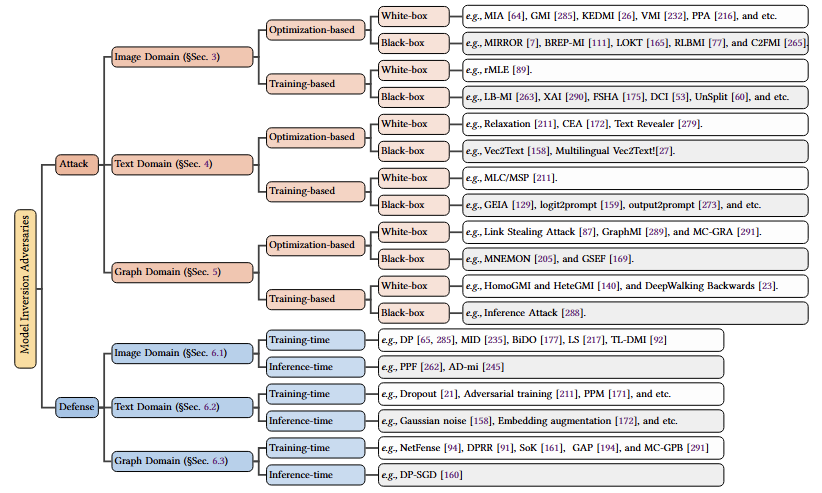 Model Inversion Attacks: A Survey of Approaches and CountermeasuresZhanke* Zhou, Jianing* Zhu, Fengfei* Yu, and 4 more authorsarXiv preprint arXiv:2411.10023, 2024* Equal contribution
Model Inversion Attacks: A Survey of Approaches and CountermeasuresZhanke* Zhou, Jianing* Zhu, Fengfei* Yu, and 4 more authorsarXiv preprint arXiv:2411.10023, 2024* Equal contributionThe success of deep neural networks has driven numerous research studies and applications from Euclidean to non-Euclidean data. However, there are increasing concerns about privacy leakage, as these networks rely on processing private data. Recently, a new type of privacy attack, the model inversion attacks (MIAs), aims to extract sensitive features of private data for training by abusing access to a well-trained model. The effectiveness of MIAs has been demonstrated in various domains, including images, texts, and graphs. These attacks highlight the vulnerability of neural networks and raise awareness about the risk of privacy leakage within the research community. Despite the significance, there is a lack of systematic studies that provide a comprehensive overview and deeper insights into MIAs across different domains. This survey aims to summarize up-to-date MIA methods in both attacks and defenses, highlighting their contributions and limitations, underlying modeling principles, optimization challenges, and future directions. We hope this survey bridges the gap in the literature and facilitates future research in this critical area.
@article{zhou2024model, title = {Model Inversion Attacks: A Survey of Approaches and Countermeasures}, author = {Zhou, Zhanke and Zhu, Jianing and Yu, Fengfei and Li, Xuan and Peng, Xiong and Liu, Tongliang and Han, Bo}, journal = {arXiv preprint arXiv:2411.10023}, year = {2024}, note = {* Equal contribution}, } -
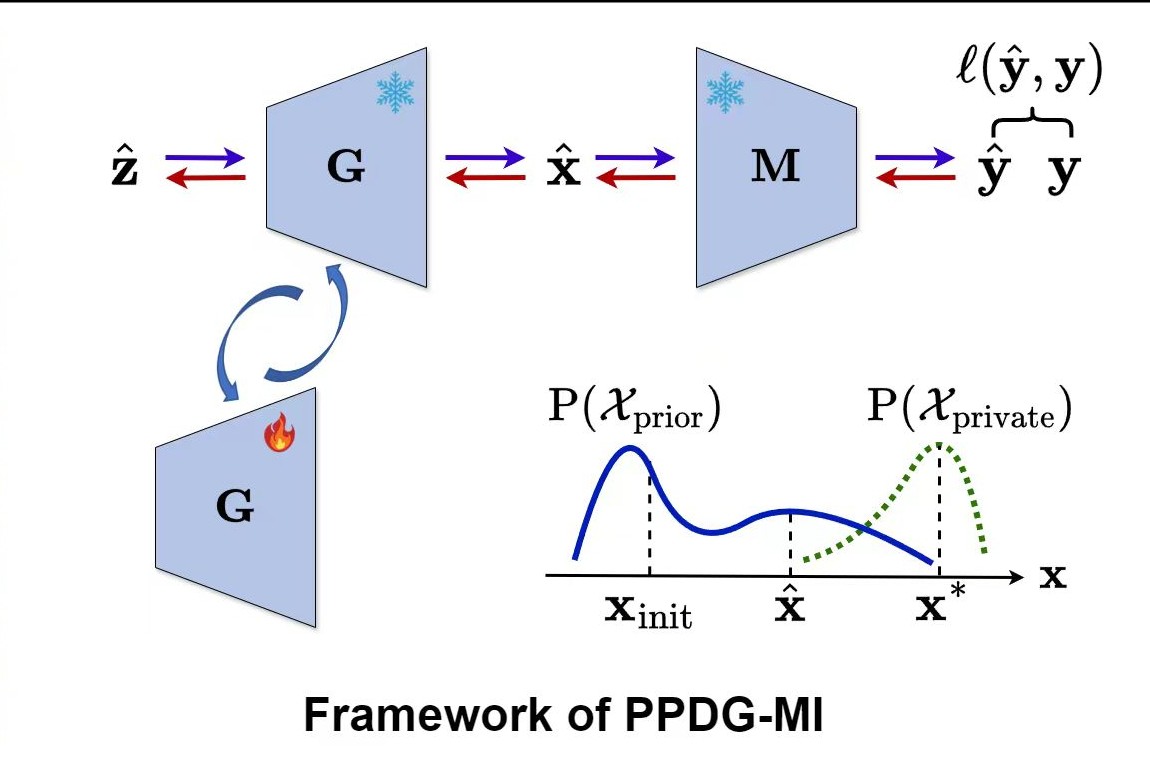 Pseudo-private data guided model inversion attacksXiong Peng, Bo Han, Feng Liu, and 2 more authorsAdvances in Neural Information Processing Systems, 2024
Pseudo-private data guided model inversion attacksXiong Peng, Bo Han, Feng Liu, and 2 more authorsAdvances in Neural Information Processing Systems, 2024In model inversion attacks (MIAs), adversaries attempt to recover the private training data by exploiting access to a well-trained target model. Recent advancements have improved MIA performance using a two-stage generative framework. This approach first employs a generative adversarial network to learn a fixed distributional prior, which is then used to guide the inversion process during the attack. However, in this paper, we observed a phenomenon that such a fixed prior would lead to a low probability of sampling actual private data during the inversion process due to the inherent distribution gap between the prior distribution and the private data distribution, thereby constraining attack performance. To address this limitation, we propose increasing the density around high-quality pseudo-private data—recovered samples through model inversion that exhibit characteristics of the private training data—by slightly tuning the generator. This strategy effectively increases the probability of sampling actual private data that is close to these pseudo-private data during the inversion process. After integrating our method, the generative model inversion pipeline is strengthened, leading to improvements over state-of-the-art MIAs.
@article{peng2024pseudo, title = {Pseudo-private data guided model inversion attacks}, author = {Peng, Xiong and Han, Bo and Liu, Feng and Liu, Tongliang and Zhou, Mingyuan}, journal = {Advances in Neural Information Processing Systems}, year = {2024}, }